I was looking around for a spreadsheet with all Y-Companies, but couldn’t find one, or at least nothing recent. The top Google Result is deprecated and leads to a website that also seems to have only old data. So I wrote a little scraper that collected the data and put it in a Google Sheet. See the bottom of this post for technical details. Or if you are here for just the sheet, click here.
The whole point of the scrape was to do some analysis and you can find that too in the sheet (done with Neptyne of course).
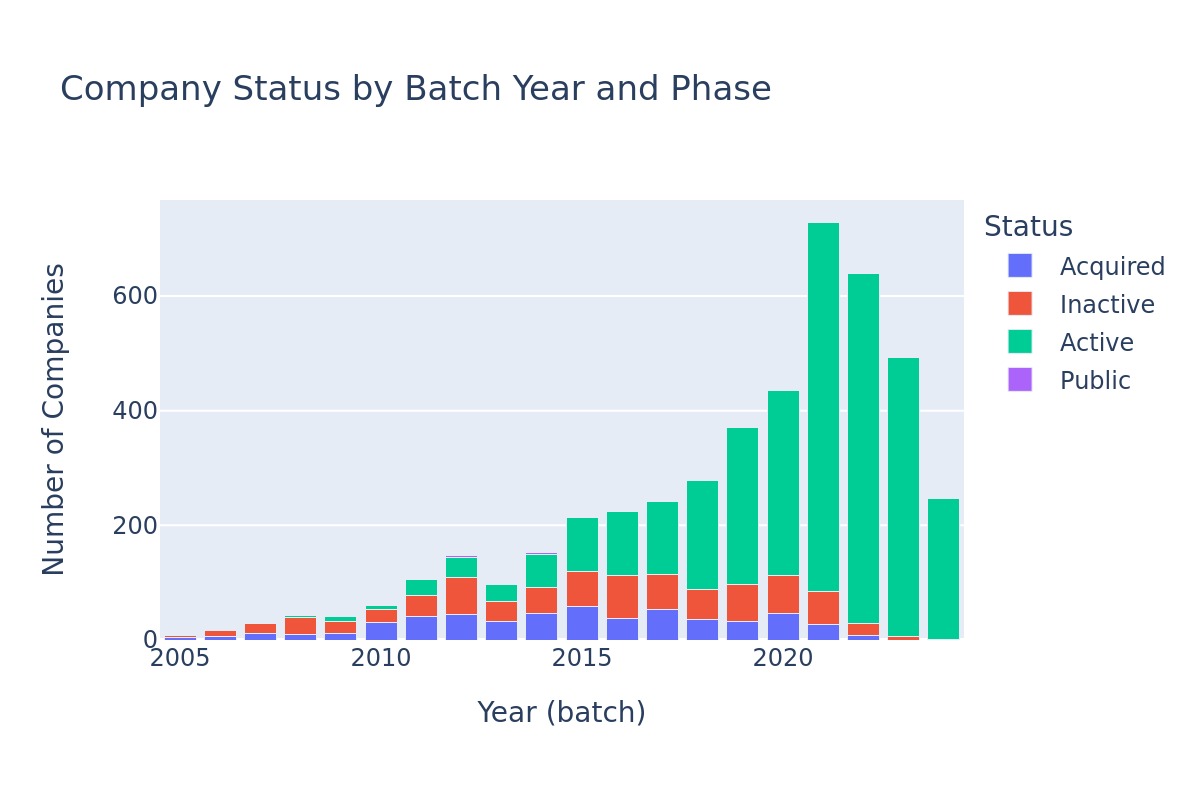
The first thing to spot here is the almost exponential growth of the number of companies that YC was backing until 2021 when it peaked at 729 (technically winter 2022 was the peak). The last bar is of course underreporting since it does not include Summer 2024 yet.
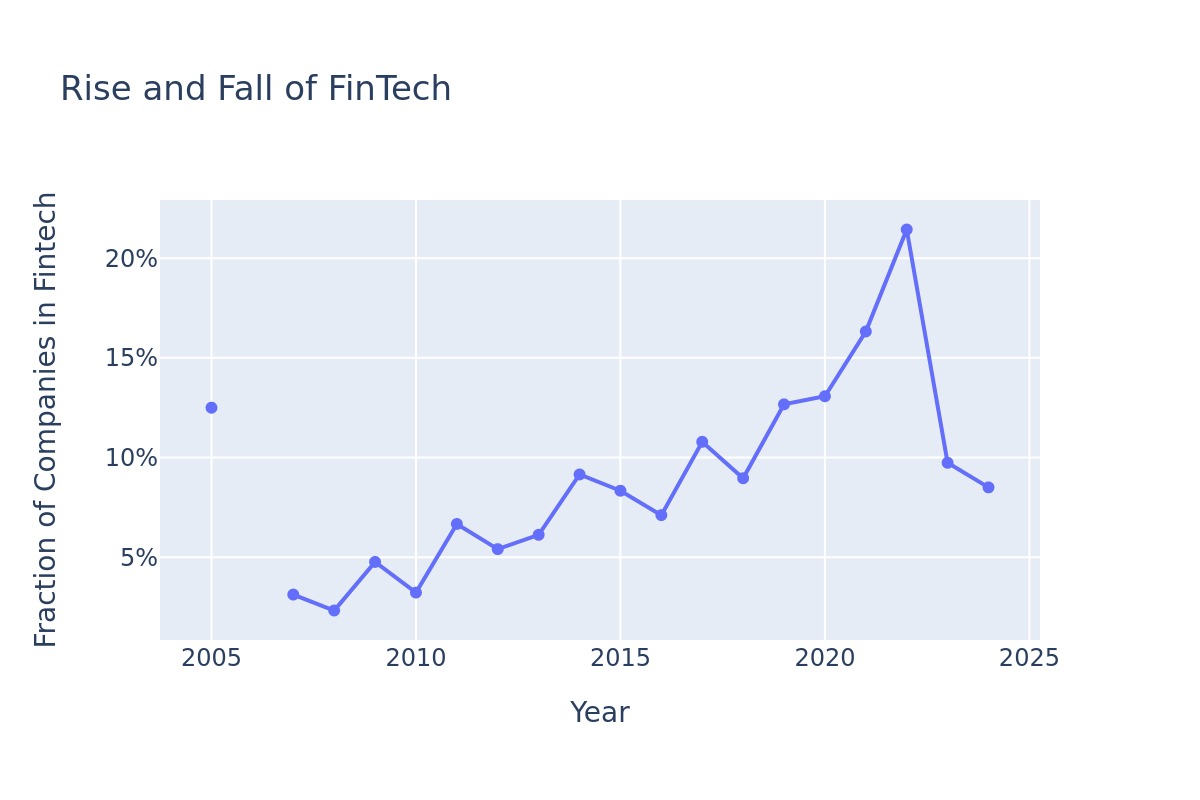
In the second graph we show the percentage of fin tech companies by year. The shape of the graph is similar, reflecting the boom in early stage investments. Fintech here also includes most crypto but crypto isn’t split out. Neither sadly is AI which would have made such a nice second line in that graph I’m sure.
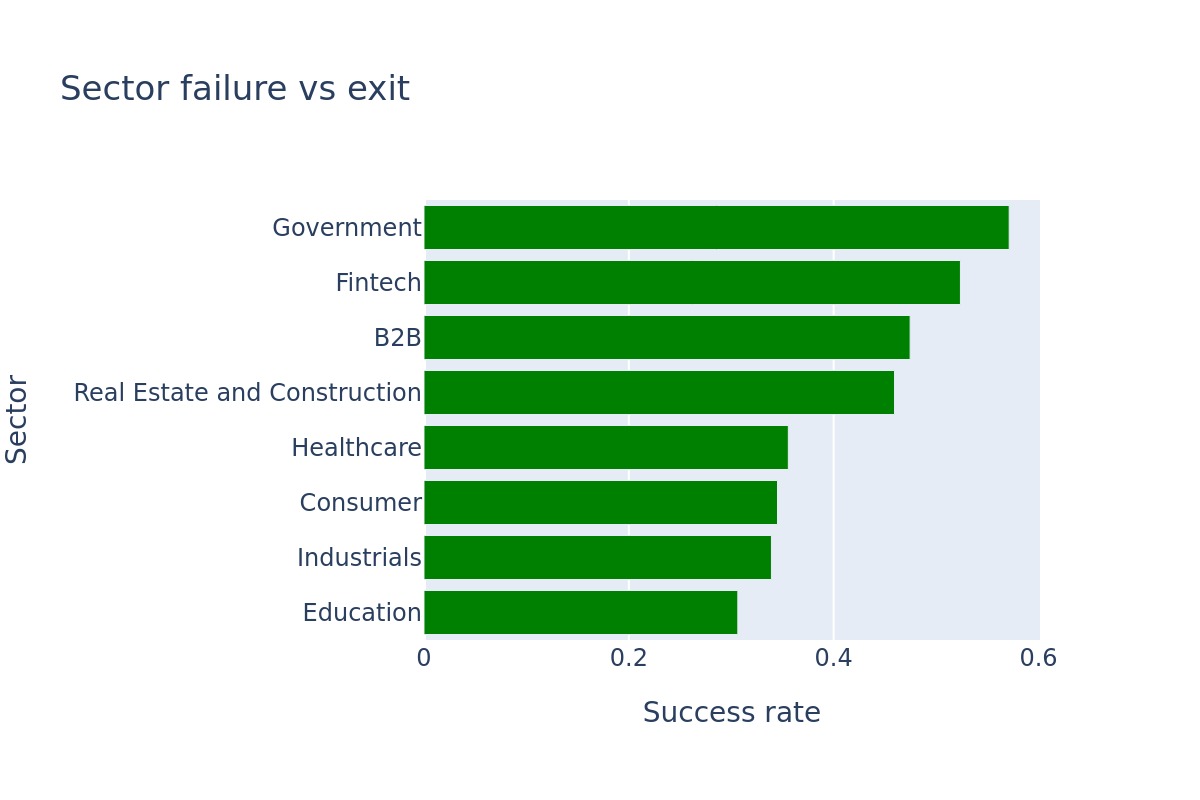
Here we see the success rate by sector, where success is the fractions of companies that either were sold or IPO’d vs all companies that are no longer active. Government oriented startups are almost twice as successful as Education ones. Maybe because Government sounds boring while Education sounds noble, change the world and all that?
Fix domains, pre or post
The final bit of analysis about the domain names. If you are a startup you probably don’t want to start by spending several hundred thousands of dollars for that perfect dot com domain. So you either use a different top level domain (.co, .io, .ai have recently been popular), or you add a little pre or post fix to your domain. You know, like thefacebook.com. Look at the table below for the most popular ones:
From that you could easily conclude that gethealth.com is the way to go. As it turns out you can buy the domain! For the low, low price of $794,888. I would have expected insta* to do better, but like it that *labs is still a thing.
How this works
If you open the spreadsheet and make a copy you can see the code (if you have the Neptyne Add-On installed that is). The scraping is pretty straightforward; YC uses algolia to implement search. You’ll need to look at the network tab of your browser to fish out the exact url since that has some access token stuff in it, so not publishing that. After that you can query two tables:
YCCompany_production: this has the actual company information in it. Does make you wonder what that _production restricts you to.
YCCompany_By_Launch_Date_production: returns a bunch of meta information
With this, we query the metadata for the batches and then get the info from the first table for all the batches. Then dump the entirety in the spreadsheet using the REPL using a simple:
B2 = download()
Most of the analytics is pretty straightforward; we can get the spreadsheet data as a dataframe with:
Batches!B2:G.to_dataframe()
And then just hand it off to plotly with the right filtering.
Getting the pre and post-fixes out is slightly more interesting. We start by making a list of all pre and post fixes and counting them using a Counter() both their number and their weights:
for cd in com_domains:
for length in range(2, len(cd)):
weight = (length - 1) ** 3
for k in cd[:length] + "*", "*" + cd[-length:]:
w_pre_post[k] += weight
c_pre_post[k] += 1
Using a **3 for the weight makes longer fragments count for more - otherwise we’d just end up with single letters as the most popular. We then remove any post & prefix that doesn’t occur at least three times.
In the next step we remove any candidate that scores less than a candidate that it either is fully contained in or it contains fully. This is to avoid seeing both *health and *ealth - if health scores well, *ealth will score less well, but might still make the cut:
for k, c in w_pre_post.most_common():
prefix = k.endswith('*')
base = k.strip('*')
for kk, cc in keep.items():
if kk.endswith('*') == prefix:
kk_base = kk.strip('*')
if base in kk_base or kk_base in base:
break
else:
keep[k] = c
We then return these sorted by their actual count.
Conclusion
Having access to the companies that YC has backed seems like a good resource to have given YCs tremendous success. The analysis run here are some basic ideas; do take it for a spin to build something more exciting and let me know!